It's just an image... Who cares about HEADERS?!

I am a developer from Newport Beach, California who specializes in full-stack web application development.
So. Images agh.
What is the process of which a visitor types in a domain address, the page loads and images come into view? How are those images loading? What is the browser doing, and more importantly what is the server doing on the other side?
...and why should I care?
HTTP — The Request
Here is what happens behind the scenes when a visitor types in the domain address and hits the enter button:
- URL (domain address and path) is parsed
- browser checks its "preloaded HSTS (HTTP Strict Transport Security)" list
- Then a DNS lookup is made which serves the correct IP address from either the browser cache, OS cache, router cache (on your local network), ISP DNS cache, or the ISP executes a recursion search for the IP address and serves it back to the browser.
- After the browser has the IP address it will open a port (either 80 or 443 for secure) and make a TLS handshake with the server
- Then browser then sends a http(s) request to the server for the index file
This is where we dive deep into the request. There are several things that the server receives when a request comes in for the index file. For simplicity, we will only discuss the HTTP and not how the requests are transmitted (you can find out more by watching this simple (90s nostalgia entertainment) video about the Warriors of the Net).
The HTTP request message can be broken down into three separate components:
- Start line — which consists of a method verb (like GET, POST, or DELETE), the path or endpoint of the request, and protocol used (HTTP/1.1)
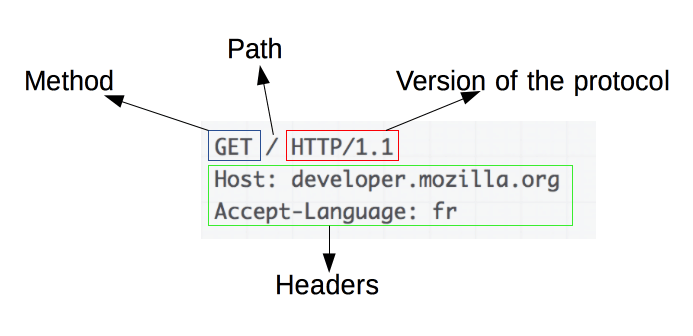
Headers — this has all the "metadata" you may heard referenced before. This tells the server all kinds of information about the browser itself, where the message was forwarded from, which compressions it accepts and information about the device.
Accept-Language en-US,en;q=0.9 Accept-Encoding gzip, deflate, br Forwarded for="67.49.70.126";proto=https Service-Worker-Navigation-Preload true Sec-Fetch-User ?1 X-Forwarded-Proto https X-Forwarded-For 67.49.70.126 Content-Length 0 Upgrade-Insecure-Requests 1 Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Referer https://www.google.com/ Sec-Fetch-Mode navigate Sec-Fetch-Dest document Sec-Fetch-Site cross-site User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36With the headers above we know that the browser is Chrome version 87 running on an Intel based Mac with an operating system of MacOS 10.12 (Sierra) which is safe to assume it's a computer that's more than 5 years old. This also tells us the IP address which was forwarded from: 67.49.70.126 When we lookup the address using ARIN the address originates from Charter Communications Inc. located in Greenwood Village, CO 80111. We also have where the user was referred from — the website domain the user was previously on to navigate to our website. In this case they were sent from https://www.google.com. which is great to know our SEO is working nicely. These headers are pretty standard for each request, but there are an unlimited number of header types. You can even custom make request and response headers to get or send information to different devices.
Body — This is where the actual content of the message resides, however, in the case of "GET" which is when the browser is requesting files, the body is empty (notice the "Content-Length" header above indicating 0 bytes).
The part we care about
All that header information about the browser and user is nice to have, but we will never use all of it for optimizing the performance and quality of images. The information most relevant to use is the following:
Accept-Encoding gzip, deflate, br
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Actually, we don't even need the Accept-Encoding either since image compression will have already been done before leaving the server. The Accept-Encoding header is for compressible files like CSS, HTML and JavaScript. If you try to gzip an already compressed image format like JPEG for example... well, you'll actually get a LARGER file size. Not good.
"Accept" the Header
There is quite a bit of information to break down in the header above. The browser is telling us which data formats it supports so it doesn't display the broken image icon to its users. If this is the first time you've seen or heard of the "Accept" header, you wouldn't be the only one. I'd say most web designers (front-end) have never utilized headers to provide the right content at the right time to its end users. Not that they are lazy or anything; mostly because they haven't needed to deal with them. With the advent of NGINX, Apache, .NET web servers, much of the header handling is done behind the scenes and web designers never need to mess with the nuts and bolts.
text/html is the polite way a browser tells the server it understand how to read and parse "text" and "html" files. Well, it better know how to do that, after all it's a browser! So why is it stating the obvious? It turns out that browsers aren't the only applications that send these Accept header type requests. More commonly application/json and application/xml are used by servers to communicate, so each device needs to let the other know which language they speak.
;q=0.9A REST API can return the resource representation in many formats – to be more specific MIME-types. This "q" parameter is the browser's way to communicate the preferred priority or 'quality' of MIME-type which ranges from 0-1. For the example above text/html, application/xhtml+xml and application/xml are priority since the quality parameter defaults to the highest "1". If the server doesn't support these MIME-types then it will try the next in the quality group. If the server still doesn't support those then it will revert to anything it can to serve the request. This is accepted by the browser by indicating the wildcard MIME-type */*.
image/avif, image/webp, and image/apng are all image MIME-types. Which is what we are after for the purpose of this article.
application/signed-exchange Signed HTTP Exchange (or "SXG") is a subset of the emerging technology called Web Packages, which enables publishers to safely make their content portable, i.e. available for redistribution by other parties, while still keeping the content’s integrity and attribution. Think of it as a tamper proof seal on a food container. When you go to the grocery store you know that the food is safe and it's exactly how it came from the food processing plant. This is extremely helpful when using a Content Delivery Network (CDN) as the data is not being sent directly from the origin server.
Taking the Red Pill
By utilizing the Accepts header from the request you are able to efficiently deliver the best possible image quality to the viewer without compromising performance; which in this case is directly correlated with the size of the image being sent both in terms of pixel size and compression efficiency.
Sounds simple right? Just grab the request headers, insert the proper image format using a template engine and presto! You can go home early.
There is a small problem though; not all browsers are created equally. The original header Accept example provided above — do you remember which browser it was? Chrome v86. The example is showing the Accept header for just that request. That Accept field changes for different requests it makes and for that one it was requesting the path or endpoint, not knowing whether it was html, xml, json, etc. or anything at all. The browser’s request is just shooting in the dark as to what to expect. We haven't even received a response from the server yet. When the HTML file is received and the browser begins the parsing process it see all kinds of links for CSS, Javascript, images, xml, etc. Each request is different.
This variable header isn't limited to just what the browser is looking for. If we were to change the browser, for example use Safari on that same device, you will receive a completely different request Accept header.
The Safari browser doesn’t actually send the server what image MIME types it accepts on the initial request for the path or endpoint. It assumes that the file it’s requesting is a ‘text/HTML’ or ‘application/XML’ file.
Our previous solution to build the HTML template with the correct image MIME types wouldn’t work in the scenario for the Safari browser. When the browser parses the HTML, it will send additional concurrent requests for links located in the HTML.
So what do we do in this situation? We could do either one of two things:
Create a “Browser Accepts” dictionary for every user agent type so that when a HTML Is requested the template engine on the server side can build and serve the correct image MIME type dynamically inside the HTML.
Or, send a generally available image format, such as JPEG, and on sequential requests replace the format type with the most optimized image file format and compression.
Both of these options are relatively easy to implement. However, the best implementation to solve both performance and compression goals is to build a service that is not dependent on constant maintenance or updates. Of the two options, the first implementation would require updating the user agent list every time a new operating system browser or device hit the market and the fact that that happens so often would bottleneck developers time and become unruly to maintain.
Number two option it is.
Now onto implementing the service. In the next few posts we will be reviewing the steps required to build and deploy this image processing. It’s not just sending the file response to the browser but also properly size and compress images to what the browser accepts.
Stay tuned...
